
Czy bufor cykliczny, ze względu na swoją prostotę, wydajność i bezpieczeństwo wielowątkowe, może być uznany za kluczową strukturę danych w oprogramowaniu wbudowanym. Przedstawiamy w artykule bufor cykliczny/kołowy jako efektywną i prostą strukturę danych, często używaną w oprogramowaniu wbudowanym, zwłaszcza dla kolejek FIFO. Zwracamy uwagę na jego szybkość działania, oszczędność pamięci i bezpieczeństwo dla wątków. Omawiamy również ograniczenia bufora przy danych o zmiennym rozmiarze oraz inne warianty, takie jak Bip Buffer, które znajdują zastosowanie w różnych obszarach.
Wybór odpowiednich struktur danych jest kluczowy dla pisania wydajnego oprogramowania. W zwykłym (nie wbudowanym) oprogramowaniu wybór struktur danych jest znacznie szerszy, ponieważ używane maszyny są potężniejsze i mają więcej pamięci. Wykorzystując dynamiczną alokację pamięci, możemy łatwo wdrożyć złożone struktury danych dostosowane do naszych potrzeb. W oprogramowaniu wbudowanym, jak zwykle, występują większe ograniczenia. Chociaż spektrum użytecznych struktur danych jest generalnie mniejsze, to nadal jest to interesujący temat.
W oprogramowaniu wbudowanym zazwyczaj staramy się unikać struktur danych z dynamiczną alokacją pamięci. Z tego powodu, kiedy to tylko możliwe, używa się prostych, stałorozmiarowych tablic elementów. Jednak czasami nasze dane wymagają bardziej "dynamicznych" struktur danych. Dwie najpopularniejsze z nich to listy połączone i bufory cykliczne.
Bufor cykliczny, znany również jako bufor pierścieniowy, to struktura danych, która często pojawia się w oprogramowaniu wbudowanym. Istnieje wiele wariantów, z których każdy ma swoje zalety i wady, w zależności od konkretnych zadań. Tutaj będziemy badać jeden ze scenariuszy, który może być mniej oczywisty.
Bufor kołowy - podstawy
Bufor cykliczny to struktura danych, która sprytnie wykorzystuje stałorozmiarową tablicę (bufor). Elementy są przechowywane w tablicy jeden po drugim, jak w zwykłym buforze, aż do osiągnięcia końca tablicy. Od tego momentu kolejne elementy są ponownie dodawane na początku tablicy - albo nadpisujemy najstarsze elementy, albo czekamy, aż zostaną usunięte, aby zwolnić miejsce w buforze.
Bufor cykliczny zazwyczaj implementuje się za pomocą dwóch wskaźników/indeksów - wskaźnika zapisu (zwykle nazywanego "głową") i wskaźnika odczytu ("ogon"). Następujący rysunek przedstawia podstawową zasadę działania:
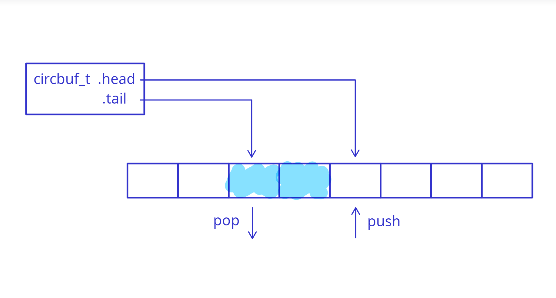
Ze względu na swoją konstrukcję, bufory cykliczne działają jako kolejki FIFO (pierwszy wchodzi, pierwszy wychodzi), dlatego są tak wszechobecne w oprogramowaniu wbudowanym. Na przykład, wyobraź sobie przetwarzanie strumienia żądań - przechowujemy żądania w buforze cyklicznym, gdy są otrzymywane, a gdy jesteśmy gotowi, przetwarzamy je w kolejności odbioru (FIFO).
Porównanie z listami połączonymi
Bufor pierścieniowy to stosunkowo prosta struktura danych, a jej główne zalety polegają na prostocie. Używanie ciągłego fragmentu pamięci o stałym rozmiarze jako bufora minimalizuje użycie pamięci - poza danymi potrzeba przechowywać jedynie dwa dodatkowe wskaźniki. Jest to również korzystne dla lokalności pamięci podręcznej, ponieważ pamięć podręczna CPU działa lepiej, gdy dane są przechowywane ciągle w pamięci. Bufor cykliczny ma złożoność wstawiania i usuwania O(1), a także złożoność dostępu losowego O(1).
jedną z głównych korzyści buforów cyklicznych jest ich zdolność do bezpiecznego używania przez dwa wątki - jeden piszący, drugi czytający - pod warunkiem, że są one dobrze zaprojektowane. Wystarczy zapewnić, że dostęp do wskaźników lub operacji odczytu i zapisu jest atomowy, czyli niepodzielny.
Lista połączona z drugiej strony to znacznie bardziej elastyczna struktura danych - może być używana nie tylko do implementacji FIFO/LIFO, ale także kilku innych struktur. Elastyczność wiąże się jednak z większym zużyciem pamięci (wskaźniki główne i dodatkowe wskaźniki na każdy element listy) i zmniejszoną lokalnością danych.
Drugi problem można zminimalizować, przechowując wszystkie elementy w stałorozmiarowej tablicy (co również rozwiązuje problem dynamicznej alokacji pamięci), ale nadal istnieje zwiększone zużycie pamięci. Lista połączona oparta na FIFO ma złożoność wstawiania/usuwania O(1), ale jest ogólnie wolniejsza niż dla bufora cyklicznego, ponieważ wiąże się z większą pracą - dostosowywaniem wskaźników elementów i potencjalną alokacją pamięci. Co więcej, lista połączona ma złożoność dostępu losowego O(n), ponieważ taki dostęp wymaga iteracji przez listę. Aby zapewnić bezpieczeństwo wątkowe przy użyciu list połączonych, musimy użyć dodatkowych prymitywów synchronizacji, takich jak mutex.
Dane o zmiennym rozmiarze
Powyższa dyskusja skupiała się na jednorodnych danych, czyli danych, gdzie rozmiar każdego elementu jest taki sam. W rzeczywistości jest to najczęstszy scenariusz - zwykle musimy kolejkować elementy tego samego typu. Jednak są sytuacje, gdy musimy pracować z elementami o różnym rozmiarze (heterogeniczne elementy). Mogą to być np. wiadomości wymieniane między dwoma urządzeniami, niektóre krótkie jak pojedynczy bajt, inne zawierające setki bajtów. Wysyłając takie dane często nie musimy śledzić, gdzie zaczyna się/skończy każda wiadomość, tylko serializujemy je do ramek protokołu i wysyłamy wszystkie powstałe bajty. Problem zwykle pojawia się podczas odczytywania takich wiadomości - musimy je kolejkować po otrzymaniu, a następnie przetwarzać, gdy jesteśmy gotowi.
Ten problem można dość łatwo rozwiązać za pomocą buforów cyklicznych. Struktura danych bufora cyklicznego pozostaje taka sama jak wcześniej, z wskaźnikami głowy/ogona. Zmienia się format danych, które przechowujemy w buforze. Każdy element jest przechowywany jako para (rozmiar, dane).
Rozmiar można przechowywać np. jako uint16_t, co minimalizuje zużycie pamięci (tylko 2 bajty na element) przy jednoczesnym umożliwieniu przechowywania elementów o rozmiarze do 65535 bajtów. Odczytując element z FIFO, najpierw sprawdzamy pierwsze bajty, aby określić rozmiar danych, a dopiero potem możemy odczytać właściwe dane. Koncepcja została przedstawiona na poniższym rysunku, gdzie każdy kolor reprezentuje inny element:
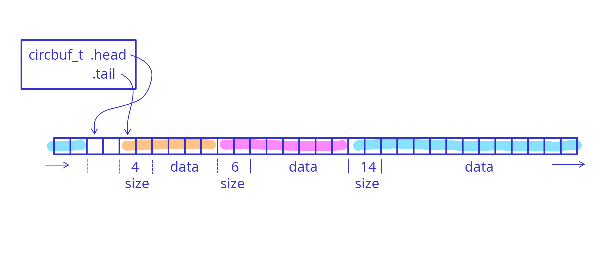
Jedną z wad takiego podejścia jest to, że nie mamy gwarancji że elementy będą ciągłe w pamięci - może się zdarzyć, że pojedynczy element "zawija się" wokół bufora. Oznacza to, że konieczne jest najpierw skopiowanie danych z bufora cyklicznego do tymczasowego bufora, zanim element zostanie użyty. Możemy oczywiście uniknąć kopiowania, dostarczając bardziej skomplikowany interfejs, ale zwykle nie jest to tego warte.
Oprócz tego otrzymujemy te same zalety, co podczas używania jednorodnych buforów cyklicznych – szybkie wstawianie/usuwanie, układ pamięci przyjazny dla lokalności pamięci podręcznej oraz bezpieczeństwo wątkowe w scenariuszach jednego producenta i jednego konsumenta. Oczywiście tracimy dostęp losowy O(1), ponieważ teraz musimy iterować po elementach, aby znaleźć n-ty element.
Podsumowanie
Bufor cykliczny to jedno z głównych narzędzi w arsenale inżyniera oprogramowania wbudowanego. Ta struktura danych jest tak prosta, a jednocześnie tak wydajna, że trudno wyobrazić sobie oprogramowanie wbudowane bez niej. I nie tylko oprogramowanie, ponieważ jest to struktura danych, która jest również implementowana w sprzęcie, aby zapewnić różnego rodzaju FIFO.
Istnieje wiele innych wariantów buforów pierścieniowych zoptymalizowanych dla konkretnych potrzeb, godnym wspomnienia jest Bip Buffer, który jest zaprojektowany, aby zawsze zapewniać ciągłe fragmenty pamięci w swoim API, co poprawia ergonomię pracy z taką strukturą danych i jest bardzo przydatne przy użyciu DMA. Mam nadzieję, że ten krótki artykuł dał ci kilka pomysłów, jak używać buforów cyklicznych w twoich projektach, jeśli jeszcze tego nie robisz!


