
Can the cyclic buffer, due to its simplicity, efficiency and multi-threaded security, be considered a key data structure in embedded software. In this article, we present the cyclic/circular buffer as an efficient and simple data structure often used in embedded software, especially for FIFO queues. We highlight its speed of operation, memory savings and safety for threads. We also discuss the limitations of the buffer when dealing with variable-size data, and other variants, such as the Bip Buffer, which find application in various areas.
Choosing the right data structures is crucial for writing efficient software. In ordinary (non-embedded) software, the choice of data structures is much wider because the machines used are more powerful and have more memory. Using dynamic memory allocation, we can easily implement complex data structures tailored to our needs. In embedded software, as usual, there are more limitations. Although the spectrum of useful data structures is generally smaller, it is still an interesting topic.
In embedded software, we usually try to avoid data structures with dynamic memory allocation. For this reason, simple, fixed-size arrays of elements are used whenever possible. However, sometimes our data requires more "dynamic" data structures. Two of the most popular of these are linked lists and cyclic buffers.
A cyclic buffer, also known as a ring buffer, is a data structure that often appears in embedded software. There are many variants, each with its own advantages and disadvantages, depending on specific tasks. Here we will explore one scenario that may be less obvious.
Circular buffer - basics
A cyclic buffer is a data structure that cleverly uses a fixed-size array (buffer). Elements are stored in the array one by one, as in a regular buffer, until the end of the array is reached. From that point on, more elements are added back to the beginning of the array - either overwriting the oldest elements or waiting until they are removed to free up space in the buffer.
A cyclic buffer is usually implemented using two pointers/indices - a write pointer (usually called the "head") and a read pointer (the "tail"). The following figure shows the basic principle of operation:
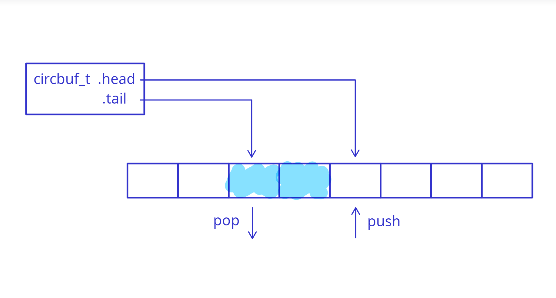
Because of their design, cyclic buffers act as FIFO queues (first in, first out), which is why they are so ubiquitous in embedded software. For example, imagine processing a stream of requests - we store requests in a cyclic buffer as they are received, and when we are ready, we process them in first-in first-out (FIFO) order.
Comparison with linked lists
The ring buffer is a relatively simple data structure, and its main advantages lie in its simplicity. Using a continuous chunk of fixed-size memory as a cache minimizes memory usage - only two additional pointers need to be stored in addition to the data. It also benefits cache locality, since the CPU cache works better when data is stored continuously in memory. A cyclic buffer has O(1) insertion and deletion complexity, and O(1) random access complexity.
One of the main benefits of cyclic buffers is their ability to be used safely by two threads - one writing, the other reading - provided they are well designed. It is sufficient to ensure that access to pointers or read and write operations is atomic, that is, indivisible.
A linked list, on the other hand, is a much more flexible data structure - it can be used not only to implement FIFO/LIFO, but also several other structures. However, flexibility comes with increased memory consumption (main pointers and additional pointers for each list element) and reduced data locality.
The second problem can be minimized by storing all elements in a fixed-size array (which also solves the problem of dynamic memory allocation), but there is still increased memory consumption. A FIFO-based linked list has an insertion/deletion complexity of O(1), but is generally slower than for a cyclic buffer because it involves more work - adjusting element pointers and potential memory allocation. Moreover, a linked list has O(n) random access complexity, since such access requires iteration through the list. To ensure thread-safety with linked lists, we need to use additional synchronization primitives, such as mutex.
Variable size data
The above discussion focused on homogeneous data, that is, data where the size of each element is the same. In fact, this is the most common scenario - we usually have to queue elements of the same type. However, there are situations when we need to work with elements of different sizes (heterogeneous elements). These can be, for example, messages exchanged between two devices, some as short as a single byte, others containing hundreds of bytes. When sending such data, we often don't need to keep track of where each message starts/ends, we just serialize it into protocol frames and send all the resulting bytes. The problem usually arises when reading such messages - we have to queue them upon receipt and then process them when we are ready.
This problem can be solved quite easily with cyclic buffers. The data structure of the cyclic buffer remains the same as before, with head/tail pointers. What changes is the format of the data we store in the buffer. Each element is stored as a pair (size, data).
The size can be stored, for example, as a uint16_t, which minimizes memory usage (only 2 bytes per element) while allowing storage of elements up to 65535 bytes. When reading an element from a FIFO, we first look at the first bytes to determine the size of the data, and only then can we read the actual data. The concept is shown in the figure below, where each color represents a different element:
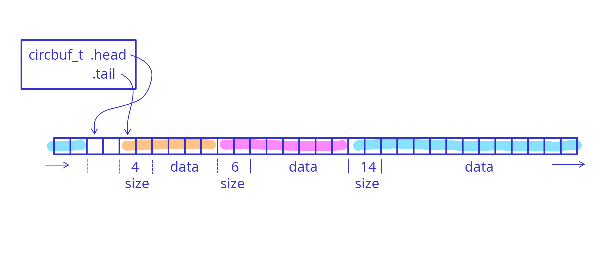
One disadvantage of this approach is that we have no guarantee that the elements will be continuous in memory - it can happen that a single element "wraps" around the buffer. This means that it is necessary to first copy the data from the cyclic buffer to a temporary buffer before the element is used. We can, of course, avoid copying by providing a more complicated interface, but it's usually not worth it.
In addition, we get the same advantages as when using homogeneous cyclic buffers - fast insertion/deletion, cache locality-friendly memory layout, and thread-safety in single-producer and single-consumer scenarios. Of course, we lose O(1) random access, since we now have to iterate through the elements to find the nth element.
Summary
The cyclic buffer is one of the main tools in an embedded software engineer's arsenal. This data structure is so simple, yet so powerful, that it's hard to imagine embedded software without it. And not just software, because it is a data structure that is also implemented in hardware to provide various types of FIFOs.
There are many other variants of ring buffers optimized for specific needs, worth mentioning is the Bip Buffer, which is designed to always provide continuous memory chunks in its API, which improves the ergonomics of working with such a data structure and is very useful when using DMA. I hope this short article has given you some ideas on how to use cyclic buffers in your projects, if you're not already doing so!


